Nossos preconceitos se refletem na inteligência artificial?

O “preconceito negativo” inerente do ser humano é derivado da nossa evolução.
Para a nossa sobrevivência, é extremamente importante sermos capazes de resolver rapidamente o perigo proveniente de uma situação, um animal ou outro humano.
Porém, nossas opiniões diferentes se evoluíram para preconceitos mais perigosos ao longo dos anos conforme culturas se mesclaram e nossa discriminação se agrava por conta de religião, casta, status social e cor da pele.
Preconceito humano e aprendizado de máquina
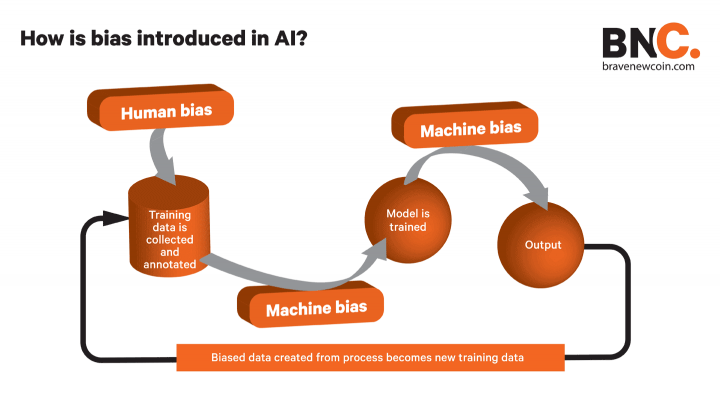
Na computação tradicional, pessoas escrevem o código de uma solução para um problema.
Com aprendizado de máquina (um subgrupo do ramo de inteligência artificial), computadores aprendem a encontrar a solução ao buscarem por padrões em dados, com os quais os humanos os alimentam.
É impossível nos separarmos de nossos próprios preconceitos humanos, então isso naturalmente alimenta a tecnologia que criamos.
Exemplos de inteligência artificial que foram um fiasco proliferam produtos de tecnologia.




Um exemplo infeliz é de quando o Google teve que pedir desculpas por taggear uma foto de pessoas negras como gorilas em seu aplicativo de fotos, que deveria autocategorizar fotos por reconhecimento facial de seus sujeitos (carros, aviões etc.).
Isso foi causado pela heurística conhecida como “preconceito de seleção”. Nikon teve um incidente parecido com suas câmeras ao serem apontadas a pessoas asiáticas que, ao focarem em seu rosto, perguntavam se “alguém está piscando”?
Possíveis preconceitos no aprendizado de máquina:
– preconceito de interação: se estamos ensinando um computador a reconhecer um objeto semelhante, como um sapato, o que o ensinamos a reconhecer é distorcido pela nossa interpretação de um sapato (masculino/feminino ou esportivo/casual) e o algoritmo só irá aprender e criar com base nisso;
– preconceito latente: se você está treinando seu programa para reconhecer um médico e sua amostra de dados é de antigos médicos famosos, o programa vai ser altamente distorcido apenas para médicos homens;
– preconceito de similaridade: ao escolher uma equipe, por exemplo, escolheríamos os que são mais parecidos conosco em vez de aqueles que achamos serem “diferentes”;
– preconceito de seleção: os dados usados para treinar o algoritmo representa uma população, fazendo com que funcione melhor para esta do que para outras.
Algoritmos e inteligência artificial devem minimizar a emoção humana e o envolvimento no processamento de dados que podem ser distorcido por falhas humanas ou muitos poderiam achar que desinfectam completamente os dados.
Porém, qualquer falha humana ou preconceito ao coletar os dados que vão para o algoritmo vão ser bem exagerados no resultado da inteligência artificial.
Preconceito de gênero no setor de fintechs
Cada indústria tem sua própria discriminação de gênero e raça, então a indústria tecnológica, assim como a indústria financeira, é dominada por homens brancos.
O Vale do Silício ganhou a reputação de “Brotopia” (algo como “utopia dos parças”) por conta da sua cultura de clube do bolinha.
A indústria de blockchain é ainda mais conhecida por sua concentração de homens brancos e jovens com experiência em Ciência da Computação, Programação ou Engenharia — e podemos regredir ainda mais para a predisposição masculina às matérias de STEM (Ciência, Tecnologia, Engenharia e Matemática) na escola.
Isso reflete na demografia de graduandos em Ciência da Computação e Tecnologia da Informação: em 2014, apenas 17% dos novos bacharéis eram mulheres.
Em 1985, 37% dos graduandos eram mulheres. De acordo com o Centro Nacional de Mulheres e Tecnologia da Informação, mulheres totalizam apenas 26% da força de trabalho em Tecnologia da Informação nos EUA, e apenas 10% delas são mulheres não brancas.
Acredita-se que apenas 1 a 5% dos investidores em criptoativos sejam mulheres. De acordo com a Forbes, mero 1,7% da comunidade inteira de bitcoin é formado por mulheres.
A situação é parecida no mercado de capital de risco, em que apenas 6% dessas empresas têm parceiras mulheres e menos de 5% do financiamento foi para startups comandadas por mulheres.
Já que o blockchain está na interseção entre finanças e tecnologia, essa questão é bem evidente, então precisamos prestar atenção no preconceito que reflete nos produtos feitos pela indústria.
Preconceito no serviço de saúde
Talvez, atualmente, o preconceito social mais amplo nos EUA seja a lacuna entre as taxas de mortalidade entre pessoas brancas e pessoas negras.
De acordo com um Relatório Nacional de Estatísticas Vitais, em 2014, a expectativa de vida média para pessoas negras nos EUA era 75,6, enquanto a média para pessoas brancas era 79,1, o que o relatório destacou ser um “nível histórico muito baixo”.
Existem muitas variáveis socioeconômicas que contribuem para isso, mas uma das discriminações mais notáveis é o no setor de saúde, pois existem mais homens brancos.
Por exemplo, os dados aleatórios apresentados à inteligência artificial, relacionados aos ensaios de controle, tende a desfavorecer mulheres, minorias étnicas e idosos, já que poucos desses grupos são selecionados para os ensaios.
Resultado: procedimentos médicos e medicamentos são aprimorados para uma demografia específica e que poderiam ser até prejudiciais para outros. Também existem poucas pesquisas feitas sobre quais efeitos os tratamentos médicos têm em grávidas.
Democratização da pesquisa científica com o blockchain
Iris.ai é uma ferramenta de inteligência artificial que ajuda pesquisadores a encontrarem artigos científicos relevantes.
Seu projeto de blockchain, Aiur, almeja reunir pesquisadores, programadores e qualquer interessado em ciência para criar um mecanismo governado por uma comunidade que acesse e contribua a um repositório válido de pesquisas científicas através do token Aiur.
A empresa quer irromper o status atual, de “uma indústria de publicação científica altamente lucrativa e oligopolista, que resultou em um modelo de incentivo desestruturado”.
Anita Schjøll Brede, CEO e cofundadora da Iris afirmou:
“Queremos um mundo onde o conhecimento científico correto esteja disponível ao nosso alcance, onde todas as pesquisas sejam confirmadas e replicáveis e onde pesquisas já pagas com nossos impostos sejam gratuitas para nós. Com o Project Aiur, queremos devolver a governança da ciência para cientistas, universidades e público.
“O mundo acadêmico nunca esteve tão produtivo. Porém, a maioria dos estudos nunca é usada, e os artigos de pesquisa usados são altamente influenciados por principais instituições acadêmicas e professores.
“Com Iris, estamos usando inteligência artificial para desenvolver uma máquina que possa ler e digerir todo esse conteúdo acadêmico”, complementou ela.
Embora existam muitas pesquisas sendo realizadas e publicadas, é muito caro acessá-las e difícil gerenciá-las. Pesquisadores são pressionados a entregar, publicar e revisar em prazos curtíssimos, criando incentivos perversos para exagerar fatos e omitir suposições e restrições.
Com pouca ou quase nenhuma responsabilidade e recompensa para autores e revisores, a reprodutibilidade é quem sofre.
Inteligência artificial tem o potencial de melhorar e muito a eficiência e objetividade no setor da saúde, desde a lista de espera de pacientes à otimização de transplantes de órgão para as pessoas que os necessitam.
Porém, isso só pode ser feito ao reconhecer quais preconceitos humanos estão sendo alimentados por essa inteligência e usar os conjuntos de dados mais diversos com as equipes mais diversas — desde o estágio de pesquisa ponto a ponto à criação do algoritmo.
Compartilhar
![[Conteúdos gratuitos] Assista ao Giro do Mercado e outros programas exclusivos em nosso Youtube](https://www.moneytimes.com.br/uploads/2024/01/banner-html-28.png)


Mais Notícias









